
Sistema MongoDB: carga de datos
En este punto del proyecto ya tenemos el sistema MongoDB listo para cargarlo con datos, así que vamos a explicar como hemos hecho la carga de datos y la réplica de los mismo a todos los nodos del sistema. Por motivos de seguridad de la información, los datos que utilizamos son antiguos y se van a cargar desde un disco duro externo. La base de datos completa está formado por muchas colecciones de documentos más los correspondientes índices, y tiene un tamaño 150GB aprox.
NoSQL en MongoDB
Primero vamos a conocer algo acerca del formato de los datos a almacenar
MongoDB utiliza un modelo de datos orientado al documento, utilizando BSON como formato de almacenamiento. BSON no es más que JSON codificado de manera binaria.
En MongoDB cada documento tiene campos para almacenar los datos. Los documentos tienen una función similar a los registros en bases relacionales.
A continuación un ejemplo del contenido de un documento
{«address»: {«building»: «1007», «coord»: [-73.856077, 40.848447], «street»: «Morris Park Ave», «zipcode»: «10462»}, «borough»: «Bronx», «cuisine»: «Bakery», «grades»: [{«date»: {«$date»: 1393804800000}, «grade»: «A», «score»: 2}, {«date»: {«$date»: 1378857600000}, «grade»: «A», «score»: 6}, {«date»: {«$date»: 1358985600000}, «grade»: «A», «score»: 10}, {«date»: {«$date»: 1322006400000}, «grade»: «A», «score»: 9}, {«date»: {«$date»: 1299715200000}, «grade»: «B», «score»: 14}], «name»: «Morris Park Bake Shop», «restaurant_id»: «30075445»}
Los documentos se agrupan en colecciones con una función parecida a las tablas del mundo relacional. La principal diferencia de las bases NoSQL con las bases relacionales es que no es necesaria una estructura fija de los documentos que contienen, ni de los tipo de datos de cada campo.
Por último, se crean los índices que son los que permiten que las búsquedas se realicen a gran velocidad dentro de las colecciones de documentos
Un link interesante para ampliar la información: https://aula301.com/cuando-usar-mongodb/
Montar disco USB en el CT
Para poder acceder a los datos ubicados en el disco externo, primero es necesario montar el disco en el servidor físico, en nuestro caso hemos usado el servidor bigdata2, y allí hemos conectado el disco externo al puerto USB. Para saber que denominación ha dado el SO al disco tecleamos
ls /dev/sd*
En nuestro caso es sda1
mount -t /dev/sda1 /mnt
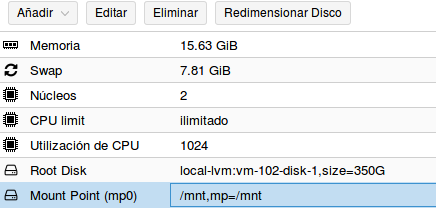
Ahora tenemos que poder acceder al punto de montaje del disco externo (/mnt) desde el contenedor, en nuestro caso mongodb2 con ID 102. Para ello, añadimos al fichero de configuración /etc /pve/lxc/102.conf una línea con:
mp0: /mnt , mp = / mnt
Con esto hemos creado un punto de montaje mp0 que permite acceder el contenido del punto de montaje /mnt del servidor físico bigdata2 (o sea, al contenido del disco externo) desde la carpeta /mnt del contenedor mongodb2
Punto de montaje del disco externo
De forma alternativa, tecleando pct 102 -mp0 / mnt , mp = / mnt logramos el mismo resultado.
Carga de datos
Antes de iniciar la copia debemos parar los servicios mongo en todos los servidores tecleando
service mongo stop
Y copiamos el contenido de una carpeta llamada apl (donde están nuestros datos) a la carpeta que definimos en la configuración de los mongo para ubicar los datos
cp -r /mnt/apl /data/mongodb/
La base de datos completa tiene aprox 150 GB por lo que la carga tardará un tiempo. Podemos comprobar que la carga se ha completado comparando el contenido de ambas carpetas con el comando de linux du
du -sh /data/mongodb
du .sh /mnt/apl
Sólo hemos cargado cargado la base de datos en uno de los mongo porque, en el siguiente paso, el propio mongo de manera automática inicia la réplica de la base en todos los demás equipos
Compártelo en tus redes






